How to recognise objects in videos with PyTorch
William Clemens (PhD)
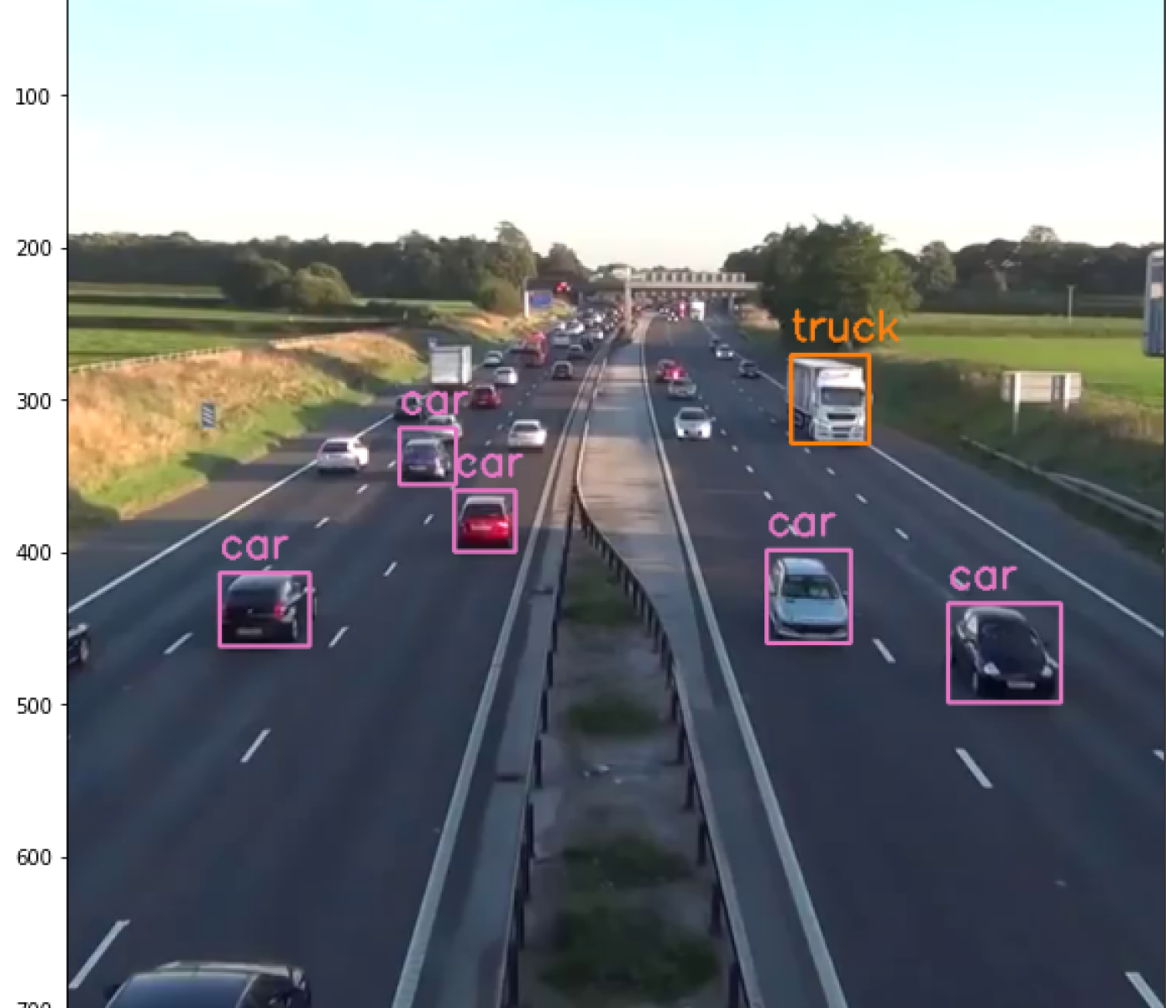
Self-driving cars still have difficulties in detecting objects in front of them with sufficient reliability. In general, though, the performance of state-of-the-art object detection models is already very impressive - and they are not too difficult to apply.
Here I will walk you through streaming a YouTube video into Python and then applying a pre-trained PyTorch model to it in order to detect objects.
We'll be applying a model pre-trained on the object detection dataset COCO. (In reality, the model would of course be fine tuned to the task at hand.)
YouTube to OpenCV
First the imports. Most of these are pretty standard for image processing and computer vision. Pafy is a video streaming library, and we will need the colourmaps from matplotlib for the bounding boxes later on.
COCO_CLASSES is just a dictionary containing the COCO class names.
We're going to use NVIDIA's implementation of the SSD using torch hub.
If you're interested in the details of the network you can read the paper here.
import numpy as np
import cv2
import pafy
import matplotlib.pyplot as plt
from matplotlib import cm
from PIL import Image
import torch
from torch import nn
from torchvision import transforms
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
url = "https://www.youtube.com/watch?v=wqctLW0Hb_0"Let's write a helper function to get an OpenCV VideoCapture object containing our YouTube video:
def get_youtube_cap(url):
play = pafy.new(url).streams[-1] # we will take the lowest quality stream
assert play is not None # makes sure we get an error if the video failed to load
return cv2.VideoCapture(play.url)Now we can just use the output of this function as a normal OpenCV VideoCapture object just like from a webcam!
We'll open up the first frame of a video just to take a look.
cap = get_youtube_cap("https://www.youtube.com/watch?v=usf5nltlu1E")
ret, frame = cap.read()
cap.release()
plt.imshow(frame[:,:,::-1]) # OpenCV uses BGR, whereas matplotlib uses RGB
plt.show()You should get this output:

Detecting objects
Ok, we can comfortably load a YouTube video, now we'll do some object detection.
To keep our code looking nice, we'll wrap up all the gory details of the implementation in a callable class.
class ObjectDetectionPipeline:
def __init__(self, threshold=0.5, device="cpu", cmap_name="tab10_r"):
# First we need a Transform object to turn numpy arrays to normalised tensors.
# We are using an SSD300 model that requires 300x300 images.
# The normalisation values are standard for pretrained pytorch models.
self.tfms = transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(300),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# Next we need a model. We're setting it to evaluation mode and sending it to the correct device.
# We get some speedup from the gpu but not as much as we could.
# A more efficient way to do this would be to collect frames to a buffer,
# run them through the network as a batch, then output them one by one
self.model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd').eval().to(device)
# Stop the network from keeping gradients.
# It's not required but it gives some speedup / reduces memory use.
for param in self.model.parameters():
param.requires_grad = False
self.device = device
self.threshold = threshold # Confidence threshold for displaying boxes.
self.cmap = cm.get_cmap(cmap_name) # colour map
self.classes_to_labels = utils.get_coco_object_dictionary()
@staticmethod
def _crop_img(img):
"""Crop an image or batch of images to square"""
if len(img.shape) == 3:
y = img.shape[0]
x = img.shape[1]
elif len(img.shape) == 4:
y = img.shape[1]
x = img.shape[2]
else:
raise ValueError(f"Image shape: {img.shape} invalid")
out_size = min((y, x))
startx = x // 2 - out_size // 2
starty = y // 2 - out_size // 2
if len(img.shape) == 3:
return img[starty:starty+out_size, startx:startx+out_size]
elif len(img.shape) == 4:
return img[:, starty:starty+out_size, startx:startx+out_size]
def _plot_boxes(self, output_img, labels, boxes):
"""Plot boxes on an image"""
for label, (x1, y1, x2, y2) in zip(labels, boxes):
if (x2 - x1) * (y2 - y1) < 0.25:
# The model seems to output some large boxes that we know cannot be possible.
# This is a simple rule to remove them.
x1 = int(x1*output_img.shape[1])
y1 = int(y1*output_img.shape[0])
x2 = int(x2*output_img.shape[1])
y2 = int(y2*output_img.shape[0])
rgba = self.cmap(label)
bgr = rgba[2]*255, rgba[1]*255, rgba[0]*255
cv2.rectangle(output_img, (x1, y1), (x2, y2), bgr, 2)
cv2.putText(output_img, self.classes_to_labels[label - 1], (int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, bgr, 2)
return output_img
def __call__(self, img):
"""
Now the call method This takes a raw frame from opencv finds the boxes and draws on it.
"""
if type(img) == np.ndarray:
# single image case
# First convert the image to a tensor, reverse the channels, unsqueeze and send to the right device.
img_tens = self.tfms(Image.fromarray(img[:,:,::-1])).unsqueeze(0).to(self.device)
# Run the tensor through the network.
# We'll use NVIDIAs utils to decode.
results = utils.decode_results(self.model(img_tens))
boxes, labels, conf = utils.pick_best(results[0], self.threshold)
# Crop the image to match what we've been predicting on.
output_img = self._crop_img(img)
return self._plot_boxes(output_img, labels, boxes)
elif type(img) == list:
# batch case
if len(img) == 0:
# Catch empty batch case
return None
tens_batch = torch.cat([self.tfms(Image.fromarray(x[:,:,::-1])).unsqueeze(0) for x in img]).to(self.device)
results = utils.decode_results(self.model(tens_batch))
output_imgs = []
for im, result in zip(img, results):
boxes, labels, conf = utils.pick_best(result, self.threshold)
output_imgs.append(self._plot_boxes(self._crop_img(im), labels, boxes))
return output_imgs
else:
raise TypeError(f"Type {type(img)} not understood")Trying it out
Now we basically have all the code written!
Let's try it out on the first video frame.
obj_detect = ObjectDetectionPipeline(device="cpu", threshold=0.5)
plt.figure(figsize=(10,10))
plt.imshow(obj_detect(frame)[:,:,::-1])
plt.show()
We can then just run over the video and write to a video file as normal in OpenCV.
This takes quite along time even on a GPU.
batch_size = 16
cap = get_youtube_cap(url)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = min([width, height])
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
out = cv2.VideoWriter("out.avi", fourcc, 20, (size, size))
obj_detect = ObjectDetectionPipeline(device="cuda", threshold=0.5)
exit_flag = True
while exit_flag:
batch_inputs = []
for _ in range(batch_size):
ret, frame = cap.read()
if ret:
batch_inputs.append(frame)
else:
exit_flag = False
break
outputs = obj_detect(batch_inputs)
if outputs is not None:
for output in outputs:
out.write(output)
else:
exit_flag = False
cap.release()Conclusion
That's it. Above I presented and explained everything you need to run your own object recognition model on any YouTube video you like. If you need more in-depth information about a machine learning subtopic to successfully realize your project, feel free to book a Tech Lunch with us.