Mit BERT automatisiert Fragen beantworten (Teil 1)
Dr. Mattes Mollenhauer

In diesem Artikel werden wir einen genaueren Blick auf BERT werfen - ein hochmodernes Modell für eine Reihe verschiedener Probleme bei der Verarbeitung natürlicher Sprache. BERT wurde von Google entwickelt und 2018 veröffentlicht und wird zum Beispiel in Googles Suchmaschine verwendet. Der Begriff BERT ist ein Akronym für den Begriff Bidirectional Encoder Representations from Transformers, der zunächst recht kryptisch erscheinen mag.
Der Artikel ist in zwei Teile gegliedert: Im ersten Teil werden wir sehen, wie BERT funktioniert, und im zweiten Teil werden wir uns einige seiner praktischen Anwendungen ansehen - insbesondere werden wir das Problem der automatisierten Beantwortung von Fragen untersuchen.
Überblick
BERT ist ein Deep Learning-Modell für Sprachrepräsentationen und dient als Pretraining-Ansatz für verschiedene NLP-Probleme (so genannte Downstream-Aufgaben). Spezifische Anwendungen sind zum Beispiel Named Entity Recognition, Sentiment Analysis und Question Answering. Das offizielle Paper, indem BERT vorgestellt wird, finden Sie hier.
Die Hauptidee von BERT besteht darin, eine unbeaufsichtigte Pretraining-Phase an einem großen generischen Textkorpus (wie z.B. Wikipedia-Artikeln oder Buchsammlungen) durchzuführen, um vernünftige Sprachrepräsentationen zu erlernen.
Während einer Feinabstimmungsphase werden die zuvor erlernten Repräsentationen als Grundlage für ein problemspezifisches Training verwendet.
Aus BERTs git repo (übersetzt):
Pretraining ist ziemlich teuer (vier Tage auf 4 bis 16 Cloud TPUs), aber es ist ein einmaliges Verfahren für jede Sprache (die aktuellen Modelle sind nur auf Englisch, aber mehrsprachige Modelle werden in naher Zukunft veröffentlicht). Wir veröffentlichen eine Reihe von vortrainierten Modellen aus dem Paper, die bei Google vortrainiert wurden. Die meisten NLP-Forscher werden nie ihr eigenes Modell von Grund auf vortrainieren müssen. Die Feinabstimmung ist kostengünstig. Alle Ergebnisse des Papiers können in höchstens einer Stunde auf einer einzelnen Cloud-TPU oder in wenigen Stunden auf einer GPU reproduziert werden, ausgehend von genau demselben vortrainierten Modell. SQuAD kann zum Beispiel in etwa 30 Minuten auf einer einzigen Cloud TPU trainiert werden, um einen Dev F1 Score von 91,0% zu erreichen, was dem Stand der Technik eines einzigen Systems entspricht.
Architektur
Die Kernkomponenten von BERT sind bidirektionale Transformatoren, die ursprünglich in diesem Paper vorgeschlagen wurden.
Die Architektur (Encoder auf der linken Seite, Decoder auf der rechten Seite) des ursprünglichen Transformators ist in der Abbildung unten dargestellt. Beachten Sie, dass die Begriffe "Encoder" und "Decoder" etwas anders interpretiert werden als z.B. bei den üblicherweise verwendeten neuronalen Faltungsnetzwerken (CNNs): Wir haben nicht die typische "Enkodierung" im Sinne von schmaler werdenden Schichten und die typische "Dekodierung" im Sinne von breiter werdenden Schichten (wie z.B. in einem Autoencoder-Netzwerk). Stattdessen konsumiert der Decoder Modell-Outputs früherer Sequenzkomponenten als Input: dies unterscheidet beide Komponenten des Netzwerks.
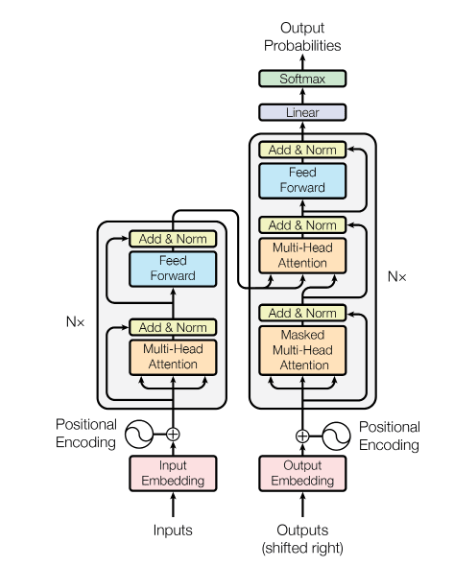
Durch das gesamten Modell hindurch finden sich so genannte residual connections (Originalpaper hier), die die attention layers überspringen (Erläuterung des Attention-Mechanismus siehe unten) und die Ausgabe einer vorhergehenden Schicht direkt in eine zusätzliche Schicht inklusive einer layer normalization (Originalpaper hier) einspeisen. Eine umfassende Einführung in Transformatoren einschließlich PyTorch-Code finden Sie hier.
Transformatoren machen sich den sogenannten Attention-Mechanismus zunutze, der in diesem Paper im Zusammenhang mit der maschinellen Übersetzung vorgeschlagen wurde. Die Idee des Attention-Mechanismus besteht darin, jeden Decoder-Output als eine gewichtete Kombination aller Eingangstoken zu erhalten. Vor diesem Ansatz erhielten die meisten NLP-Aufgaben, die auf RNNs basieren, gewöhnlich eine Ausgabe aus einem einzigen aggregierten Wert aller vorhergehenden Objekte in der Eingabesequenz. Dies ist vor allem bei langen Eingabesequenzen ein ziemlich großes Problem, da die Information am Ende der Eingabesequenzen alle vorhergehenden Sequenzkomponenten komprimiert und dadurch möglicherweise viel Rauschen verursacht. Sehen Sie hier die Visualisierung des Attention-Mechanismus (in diesem Fall mit einem bidirektionalen RNN) aus dem Originalpaper:
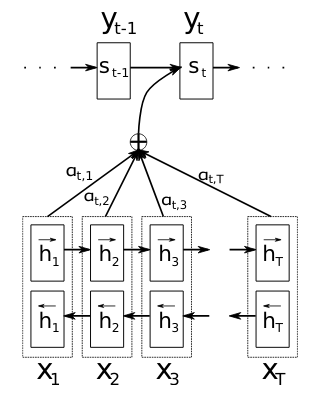
Die Idee ist, dass der auf dem Attention-Mechanismus basierende Kodierungs-/Dekodierungsprozess nun die jeweilige Aufgabe (wie z.B. die Übersetzung) in Kombination mit einer "Alignmentsuche" durchführt, d.h. er lernt zusätzlich, wie jede einzelne der individuellen Eingabesequenzkomponenten an der resultierenden Ausgabesequenz beteiligt ist, anstatt nur eine vorgegebene Ausgabereihenfolge über eine "klassische" End-to-End-RNN-Dekodierung zu durchlaufen. Diese Operation ist in der obigen Abbildung in Form der Gewichte $$\alpha_{t,i}$$ visualisiert, die den Einfluss der $$i$$-ten Eingangskomponente auf die $$t$$-te Ausgangskomponente bestimmen (wiederum in diesem Fall mit einem bidirektionalen RNN-Modell anstelle des Transformators, der in BERT verwendet wird).
Beim Transformator werden mehrere attention layer gestapelt, um die Encoder- und Decoderstrukturen zu erhalten.
Die ursprüngliche BERT-Implementierung gibt es in zwei Modellgrößen: ein BERT-Basismodell mit einer hidden middle layer-Größe von $$H=768$$ Dimensionen und ein großes BERT-Modell mit einer hidden layer-Größe von $$H=1024$$ Dimensionen. Die Encoder/Decoder-Blöcke bestehen aus $$12$$ und $$24$$ Schichten von Transformatoren. Alle im Modell enthaltenen Schichten haben die gleiche Größe - beachten Sie, dass dies auch für die residual connections erforderlich ist.
Input-Repräsentationen und Tokenization
Das ursprüngliche BERT-Modell kann entweder einen einzelnen Satz oder zwei Sätze (die wir im Folgenden Eingabesegmente/-sätze nennen werden) als Tokensequenz-Eingabe verwenden, was BERT flexibel für eine Vielzahl von nachgelagerten Aufgaben macht. Die Fähigkeit, zwei Sätze zu verarbeiten, kann zum Beispiel für Frage/Antwort-Paare verwendet werden. BERT wird mit einem eigenen Tokenisierungwerkzeug geliefert.
Als Eingabedarstellung verwendet BERT WordPiece-Einbettungen, die in diesem Paper vorgeschlagen wurden. Bei einem Vokabular von ~30k Wortstücken zerlegt BERT Wörter in Komponenten - was zu einer Tokenisierung $$[t_1, \dots, t_l]$$ für eine Eingabesequenz der Länge $$l$$ führt. Wir werden uns die Tokenisierung weiter unten genauer ansehen. Eine Erläuterung des BERT-Vokabulars finden Sie hier.
WordPiece ist ein eigenständiges Sprachrepräsentationsmodell. Bei einer gewünschten Vokabulargröße versucht WordPiece, die optimalen Token (= Unterwörter, Silben, Einzelzeichen etc.) zu finden, um eine maximale Anzahl von Wörtern im Textkorpus zu beschreiben.
Wichtig dabei ist, dass WordPiece getrennt von BERT trainiert und im Wesentlichen als Black Box verwendet wird, um die Vektorisierung von Eingabesequenzen in einem festen Vokabular durchzuführen. Dieser Vorgang wird für jedes Wort in der Eingabe nach einer allgemeinen String-Bereinigung durchgeführt. Der Haken an der WordPiece-Idee ist, dass BERT einen relativ großen Katalog von Wörtern mit einem Vektor fester Dimension darstellen kann, der dem Vokabular der Wortstücke entspricht. Es gibt mehrere Möglichkeiten, mit Token mit Wortbestandteilen außerhalb des Vokabulars umzugehen, siehe das oben verlinkte Original-WordPiece-Papier. Die von WordPiece generierten Token werden normalerweise den IDs im entsprechenden Vokabular zugeordnet, um eine numerische Darstellung der Eingabesequenz zu erhalten. Bei diesen IDs handelt es sich in der Regel nur um die Nummer des Index in der Vokabelliste (es ist jedoch auch möglich, Hash-Funktionen auf die Token anzuwenden). Es ist eigentlich ziemlich einfach, eine manuelle WordPiece-Tokenisierung durchzuführen, indem man das Vokabular aus der Vokabeldatei eines der vortrainierten BERT-Modelle und das Tokenizer-Modul aus dem offiziellen BERT-Repository verwendet.
from tokenization import FullTokenizer
# load BERTs WordPiece vocabulary
tokenizer = FullTokenizer("cased_L-12_H-768_A-12/vocab.txt")
test_sequence = """
This is a test sequence for BERTs tokenization based on the WordPiece approach.
"""
tokens = tokenizer.tokenize(test_sequence)
print(tokens)['this', 'is', 'a', 'test', 'sequence', 'for', 'be', '##rts', 'token', '##ization', 'based', 'on', 'the', 'word', '##piece', 'approach', '.']Die Zeichen ## zeigen an, dass das Token mit dem vorhergehenden Token verbunden ist (z.B. durch Zerlegung eines einzelnen Wortes in Token). Im Fall von BERT ist die numerische Repräsentation der Token lediglich die Abbildung auf ihre Indizes im Vokabular:
tokenizer.convert_tokens_to_ids(tokens)[1142,
1110,
170,
2774,
[...]
9641,
3136,
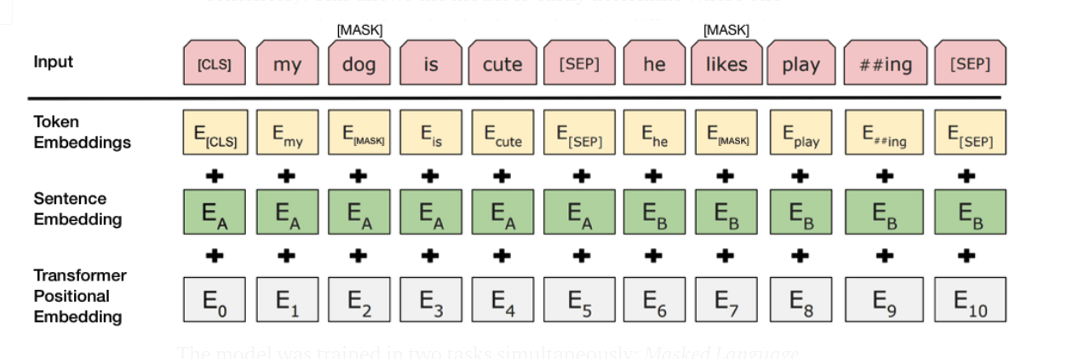
119]Falls zwei Sätze an BERT übergeben werden, werden sie mit Hilfe eines speziellen [SEP]-Tokens getrennt. Alle Eingaben beginnen mit einem [CLS]-Token, das den Beginn einer Tokensequenz anzeigt und später als Repräsentation für Klassifikationsaufgaben verwendet wird (siehe den Abschnitt über das Pretraining weiter unten).
Die Token-Einbettungen werden mit Nachschlagetabellen zur Worteinbettung verglichen und werden zur sogenannten Token-Eingabeeinbettung $$E_{ti} \in \mathbb{R}^H$$ (wieder ist $$H$$ die Dimensionalität der hidden layers von BERT, wie oben eingeführt). Interessanterweise ist neben der "flachen" Token-Zuordnung zu ihren IDs auch eine One-Hot-Codierungsversion der Token im Quellcode von BERT enthalten.
Angenommen, wir haben nun die Token-Einbettungen $$E_{ti}$$ erhalten (d.h. Worteinbettungen, die entweder aus einer Zuordnung von Token zu IDs oder einer One-Hot-Codierung generiert wurden), dann wird eine erlernte Satzeinbettung $$E_A \in \mathbb{R}^H$$ oder $$EB \in \mathbb{R}^H$$ addiert, je nachdem, zu welchem Satz das Token gehört.
Als dritte Information verwendet BERT eine Einbettung der Token-Position in der Eingabesequenz: die positionelle Einbettung $$E_i \in \mathbb{R}^H$$ entsprechend dem Token $$t_i$$. Positionale Einbettungen sind Vektoren der gleichen Größe wie die beiden anderen Einbettungen. Die positionale Einbettung ist erforderlich, da das BERT selbst keine intrinsische sequentielle Ordnung wie z.B. ein rekurrierendes neuronales Netz besitzt. Im ursprünglichen Paper, das das sogenannte transformer layer (siehe Abschnitt unten) vorschlug, wurde eine Einbettungsregel in Form eines aus Sinuskurven bestehenden Vektors vorgeschlagen. Insbesondere bezeichne $$E_{i,j}$$ den $$j$$-ten Eintrag des Positionskodierungsvektors $$E_i \in \mathbb{R}^H$$, der sich auf den Token $$t_i$$$ bezieht. Die im ursprünglichen Transformatorpapier verwendete Einbettungsregel lautet dann
sowie
für alle $$ 1 \leq j \leq \lfloor{H/2}\rfloor$$.
Auch das Erlernen der positionellen Einbettungen wurde vorgeschlagen. Das ursprüngliche BERT-Papier geht nicht näher darauf ein, welche positionellen Einbettungen gewählt werden. Es wird jedoch erwähnt, dass die Implementierung auf dem Papier basiert, welches das transformer layer einführt.
Für jedes Eingabe-Token $$t_i$$ wird dann die Token-Einbettung $$E_{ti}$$, die Positionseinbettung $$E_i$$ und der entsprechende Satz-Einbettungsvektor $$E_A/E_B$$ summiert, um die endgültige Eingabe-Einbettungsdarstellung für die $$i$$-te Eingabe für BERT zu erhalten.
Durch die Propagierung dieser Eingabedarstellung durch das vollständige Modell erhalten wir dann die endgültige verborgene Einbettung $$T_i \in \mathbb{R}^H$$ aus dem Token $$t_i$$ (siehe Bild im Abschnitt unten).
Pretraining
Pretraining of BERT is performed in an unsupervised manner on fairly large unlabeled text corpora (such as Wikipedia articles). The original BERT version was trained on the BooksCorpus and English Wikipedia. During the pretraining phase, BERT performs two particular tasks:
1. Masked Language Modeling:
In order to learn the connection between smaller text components such as words and tokens, tokens of the input sequences are chosen at random (15% of the original input sequence tokens). Among these selected tokens, a word replacement routine with a [MASK] token is performed. In order to not introduce a model bias towards the mask token, a small percentage of the selected tokens are replaced with a randomly chosen token or remain unchanged. The hidden representation of the input tokens will then be used in combination with a softmax classifier in order to predict the selected tokens from BERTs vocabulary under a cross entropy risk.
2. Next Sentence Prediction:
This task is performed in order to learn connections between sentences. From the available text corpora, sentence pairs are formed. Whenever the pairs are subsequent in the original text, a IsNext label is attached to them. Whenever the sentence pairs are not subsequent in the original texts, a NotNext label is attached. The training dataset is generated of 50% pairs with IsNext label and 50% NotNext label. BERT now predicts the two labels as a binary classifier based on the hidden layer embedding of the [CLS] token of the input sequence. The left side of the image below visualizes how the hidden representations $$C \in \mathbb{R}^H$$ and $$T_i \in \mathbb{R}^H$$ of the [CLS] token and the text segment token $$t_i$$ are used for these tasks.
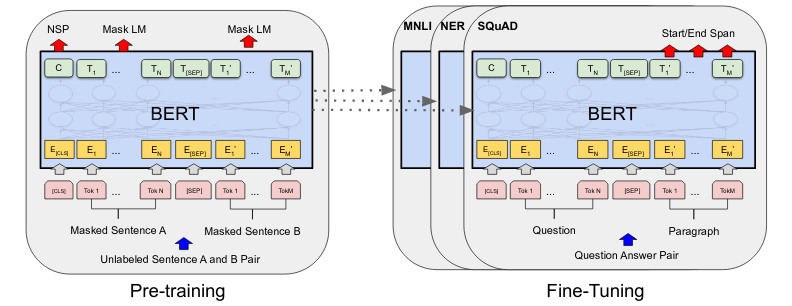
Fine-tuning
Fine-tuning of BERT is always associated with a particular practical task such as for example classification. The pretraining version of BERT (that is, the weights obtained from the Masked Language Modeling and Next Sentence Prediction training routines outlined above) are used as starting weights for a supervised learning phase.
Depending on the specific task, various components of BERTs input can be used. For a text sequence classification task, the representation of the [CLS] token will be used. For tasks involving two sentence inputs such as paraphrasing and question/answer problems, we make use of the sentence $$A$$/$$B$$ mechanism described in the previous sections.
Usually, additional neurons/layers are added to the output layer of BERT: in the classification case this could for example be a softmax output. Given a training data set, a standard end-to-end training routine for the full BERT model with the task-specific modified output layers is run. Typically, the fine-tuning phase is a much faster procedure than the pretraining phase, since the transfer from Masked Language Modeling and Next Sentence Classification to the particular fine-tuning task allows to start from a near-converged state.
Outlook
That's it for the first part of the article. In the second part we are going to examine the problem of automated question answering via BERT. You can also read about a project we did for idealo, where we used different BERT models for automatic extraction of product information.
References
A Neural Named Entity Recognition and Multi-Type Normalization Tool for Biomedical Text Mining; Kim et al., 2019.
Attention Is All You Need; Vaswani et al., 2017.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding; Devlin et al., 2018.
BioBERT: a pre-trained biomedical language representation model for biomedical text mining; Lee et al., 2019.
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation; Wu et al., 2016.
Neural machine translation by jointly learning to align and translate; Bahdanau et al. 2015.
Pre-trained Language Model for Biomedical Question Answering; Yoon et al., 2019.
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index; Seo et al., 2019.
The Annotated Transformer; Rush, Nguyen and Klein.