Ensembles im maschinellen Lernen: Das Kombinieren mehrerer ML-Modelle
Serdar Palaoglu

In der sich ständig weiterentwickelnden Welt des maschinellen Lernens hat das Streben nach besserer Vorhersagegenauigkeit zur Entwicklung von Ensemble-Methoden geführt. Diese Verfahren nutzen die kollektive Leistung mehrerer Modelle, um eine bessere Leistung zu erzielen als jedes einzelne Modell für sich allein. Dieser Artikel befasst sich mit dem Ensemble-Lernen und untersucht, wie die Kombination verschiedener Algorithmen zu robusteren, verallgemeinerbaren und genaueren Lösungen für maschinelles Lernen führen kann.
Was bedeutet Ensemble beim maschinellen Lernen?
Beim maschinellen Lernen bezieht sich ein Ensemble auf eine Sammlung von mehreren Modellen, die zusammenarbeiten, um eine Vorhersage oder Klassifizierung zu erstellen. Die Idee ist, die Stärken der einzelnen Modelle zu kombinieren, um die Gesamtleistung zu verbessern und Fehler zu reduzieren. Durch die Zusammenfassung der Ergebnisse mehrerer Modelle erreicht ein Ensemble oft eine bessere Vorhersageleistung als jedes einzelne Modell innerhalb des Ensembles.
Einfache Analogie
Das Konzept des Ensemble-Lernens lässt sich anhand einer einfachen Analogie verstehen. Stellen Sie sich vor, Sie versuchen, ein komplexes Problem zu lösen, und Ihnen stehen mehrere Experten zur Verfügung. Jeder Experte hat sein eigenes Fachgebiet und seine eigene Herangehensweise an die Lösung des Problems. Würden Sie jeden von ihnen um eine Lösung bitten und dann ihre Erkenntnisse kombinieren, wäre die resultierende Lösung wahrscheinlich genauer und umfassender als wenn Sie sich auf einen einzelnen Experten verlassen würden. Beim maschinellen Lernen ist jeder "Experte" ein Vorhersagemodell, das mit Daten trainiert wurde.
Ensemble Techniken
Es gibt verschiedene Techniken zur Erstellung von Ensembles, die sich grob in drei Typen einteilen lassen: Bagging, Boosting und Stacking.
Bagging
Bootstrap-Aggregation, allgemein bekannt als Bagging, ist eine Methode, die die Konzepte des Bootstrapping und der Aggregation zu einem einheitlichen Ensemble-Modell zusammenführt. Bei diesem Ansatz werden aus einer Datenstichprobe mehrere Teilmengen erzeugt, von denen jede eine Bootstrap-Replik darstellt. Für jede Teilmenge wird ein eigener Entscheidungsbaum erstellt. Sobald alle Entscheidungsbäume aus den Teilstichproben erstellt sind, werden sie durch einen Algorithmus kombiniert, der ihre Ergebnisse integriert, um das effektivste Vorhersagemodell zu erstellen.
Bagging adopts the bootstrap distribution for generating different base learners. In other words, it applies bootstrap sampling to obtain the data subsets for training the base learners.
— Zhi-Hua Zhou, "Ensemble Methods: Foundations and Algorithms"
Boosting
Beim Boosting hingegen werden die Modelle nacheinander trainiert, wobei jedes neue Modell versucht, die Fehler der vorherigen Modelle zu korrigieren. Algorithmen wie AdaBoost und Gradient Boosting sind Beispiele für Boosting-Methoden. Sie beginnen mit einem schwachen Modell und fügen iterativ weitere Modelle hinzu, wobei sie die Gewichtung von Instanzen anpassen, die von den vorherigen Modellen falsch klassifiziert wurden, um die Leistung schrittweise zu verbessern.
Der Lernalgorithmus passt seinen Fokus auf die Trainingsdaten an, indem er schwer vorhersagbaren Beispielen mehr Gewicht gibt und so effektiv aus den Fehlern der früheren Modelle lernt. Boosting wurde theoretisch vorgeschlagen, bevor es sich in der Praxis durchsetzte, wobei der AdaBoost-Algorithmus die erste effektive Implementierung darstellte. Seitdem hat sich das Boosting weiterentwickelt, wobei Techniken wie Gradient Boosting Machines und Stochastic Gradient Boosting (z. B. XGBoost) zu den leistungsfähigsten Methoden für die Verarbeitung strukturierter Daten gehören.
Stacking
Stacking-Ensemble-Lernen, auch bekannt als gestapelte Generalisierung, ist eine Methode, die mehrere verschiedene Vorhersagemodelle kombiniert, um die Gesamtleistung zu verbessern. Bei diesem Ansatz werden mehrere Modelle der ersten Ebene (Basis-Learner) auf denselben Daten trainiert und dann ein Modell der zweiten Ebene (Meta-Learner) verwendet, um deren Vorhersagen zusammenzufassen.
Der Meta-Learner wird so trainiert, dass er den besten Weg findet, die Vorhersagen der Basis-Learner zu kombinieren und so effektiv von ihren unterschiedlichen Stärken zu lernen. Diese Technik ermöglicht die Verwendung verschiedener Arten von Algorithmen für maschinelles Lernen als Basis-Learner, was zu einer großen Vielfalt im Ensemble beiträgt und in der Regel zu weniger korrelierten Fehlern führt. Stacking ist für seine Fähigkeit bekannt, die Vorhersagekraft mehrerer Modelle zu nutzen, und bildet die Grundlage für viele fortgeschrittene Ensemble-Techniken.
Sie können beispielsweise einen Entscheidungsbaum, eine Support Vector Machine und ein neuronales Netz trainieren und dann ein Metamodell wie die logistische Regression verwenden, um deren Vorhersagen zu kombinieren. Das Metamodell lernt effektiv, die Stärken und Vorhersagen der einzelnen Basismodelle zu kombinieren, um die endgültige Vorhersagegenauigkeit zu verbessern, was zu einer besseren Leistung führen kann, als jedes der einzelnen Modelle für sich allein erreichen könnte.
Warum verwenden wir beim maschinellen Lernen ein Ensemble?
Einer der überzeugendsten Gründe für den Einsatz von Ensemble-Methoden ist ihre Fähigkeit, die Überanpassung zu reduzieren. Dies ist ein häufiges Problem beim maschinellen Lernen, bei dem ein Modell bei den Trainingsdaten gut abschneidet, bei neuen, unbekannten Daten jedoch schlecht. Durch die Aggregation der Vorhersagen mehrerer Modelle können Ensemble-Methoden die Verzerrungen glätten und die Varianz reduzieren, was zu einem allgemeineren Modell führt. Dies ist besonders nützlich bei Anwendungen, bei denen die Kosten einer falschen Vorhersage hoch sind, wie z. B. bei der medizinischen Diagnose oder im Bank- und Finanzwesen.
Außerdem kann die Leistung eines Modells beim maschinellen Lernen in drei Komponenten zerlegt werden: Verzerrung, Varianz und irreduzibler Fehler.
Der Bias bezieht sich auf den Fehler, der durch zu vereinfachende Annahmen im Lernalgorithmus entsteht. Ein hoher Bias kann dazu führen, dass das Modell relevante Beziehungen zwischen Merkmalen und Zieloutputs übersieht, was zu einer Unteranpassung führt. Andererseits bezieht sich die Varianz auf den Fehler, der auf eine zu hohe Komplexität des Lernalgorithmus zurückzuführen ist. Eine hohe Varianz kann zu einer Überanpassung führen, bei der das Modell das zufällige Rauschen in den Trainingsdaten erlernt.
Ensemble-Methoden, insbesondere solche, die eine Randomisierung beinhalten, wie Bagging und Random Forests, bieten eine Möglichkeit, diesen Zielkonflikt besser zu bewältigen. Durch die Kombination mehrerer Modelle können Ensemble-Methoden die Verzerrung geringfügig erhöhen, die Varianz jedoch oft erheblich verringern. Der Schlüssel hierzu ist die Korrelation zwischen den Modellen. Wenn die Modelle nicht korreliert sind, kann das Ensemble die Varianz erheblich reduzieren, ohne dass die Verzerrung wesentlich zunimmt, was zu einem robusteren Modell führt. Der Grad der Zufälligkeit, der in Ensemble-Methoden eingeführt wird, dient als Kontrollregler für diesen Kompromiss zwischen Verzerrung und Varianz. Zu viel Zufälligkeit kann die Verzerrung erhöhen, während zu wenig Zufälligkeit es dem Ensemble möglicherweise nicht ermöglicht, die Varianz wirksam zu reduzieren.
Wenn Sie diese Modelle zu einem Ensemble kombinieren, können sich diese unterschiedlichen Fehler gegenseitig ausgleichen, was zu einem insgesamt robusteren und genaueren Modell führt. An dieser Stelle kommt das Konzept der "Varianzreduzierung" ins Spiel. Die Varianz gibt im Wesentlichen an, wie sehr sich die Vorhersagen Ihres Modells ändern würden, wenn Sie einen anderen Trainingsdatensatz verwenden würden. Durch die Einführung von Zufälligkeiten sind die Vorhersagen der einzelnen Modelle weniger miteinander korreliert, was bedeutet, dass sie wahrscheinlich unterschiedliche Varianzen aufweisen. Wenn Sie diese Vorhersagen in einem Ensemble zusammenfassen, gleichen sich auch die Varianzen aus, was zu einem Modell mit geringerer Gesamtvarianz führt.
Sind Ensembles beim maschinellen Lernen die Zukunft?
Ensemble-Methoden könnten aus mehreren zwingenden Gründen als die Zukunft des maschinellen Lernens angesehen werden.
Erstens bieten sie eine Möglichkeit zur Verbesserung der Modellleistung, ohne dass neue, komplexere Algorithmen erforderlich sind. Durch die Kombination bestehender Modelle erreichen Ensemble-Methoden oft eine höhere Genauigkeit und eine bessere Generalisierung auf neue Daten. Dies ist entscheidend für Anwendungen, bei denen eine hohe Vorhersagegenauigkeit erforderlich ist, wie z. B. in der Gesundheitsdiagnostik, bei Finanzprognosen und bei autonomen Fahrzeugen.
Zweitens sind Ensemble-Methoden sehr anpassungsfähig. Sie können sowohl auf Klassifizierungs- als auch auf Regressionsprobleme angewandt werden, und sie können verschiedene Arten von Modellen einbeziehen. Dank dieser Flexibilität eignen sie sich für eine breite Palette von Anwendungen und können an die sich entwickelnde Landschaft der Algorithmen für maschinelles Lernen angepasst werden. Wenn neue Modelle entwickelt werden, können sie problemlos in bestehende Ensembles integriert werden, wodurch die Leistung kontinuierlich verbessert wird.
Drittens sind Ensemble-Methoden besonders gut im Umgang mit vielfältigen und großen Datensätzen. In der Ära von Big Data, in der Datensätze sehr umfangreich und hochdimensional sein können, bieten Ensemble-Methoden eine Möglichkeit, diese Komplexität zu bewältigen. Sie können mit verschiedenen Arten von Merkmalen, fehlenden Werten und Ausreißern umgehen, was sie robust gegenüber den vielen Herausforderungen macht, die große Datensätze mit sich bringen.
Zu guter Letzt sind Ensemble-Lernmethoden von Natur aus parallelisierbar, so dass sie auf mehreren Prozessoren, auf mehreren Rechnern in Netzwerken wie Bittensor laufen können.
Durch die Verteilung der Modellinferenzaufgaben über ein Netzwerk können Ensemble-Methoden gleichzeitig verarbeitet werden. Dies maximiert nicht nur die Effizienz der Ressourcennutzung, sondern entspricht auch dem Trend zu mehr dezentralisierten und kollaborativen Berechnungsrahmen. Aufgrund ihrer Parallelität eignen sich Ensemble-Methoden besonders gut für komplexe Berechnungen, die von der Robustheit und kollektiven Intelligenz mehrerer Modelle profitieren, die zusammenarbeiten.
Was ist ein Beispiel für Ensemble-Lernen?
Random Forest Algorithmus
Ein klassisches Beispiel für Ensemble-Lernen ist der Random-Forest-Algorithmus. Ein Random Forest ist ein Ensemble von Entscheidungsbäumen, die im Allgemeinen mit der Bagging-Methode trainiert werden. Die Idee ist einfach, aber wirkungsvoll: Erstellen Sie während des Trainings mehrere Entscheidungsbäume und lassen Sie sie für die beliebteste Klasse abstimmen (oder den Durchschnitt der Ergebnisse bei Regressionsproblemen), um eine Vorhersage zu treffen.
In einem Random Forest wird jeder Entscheidungsbaum auf einer Teilmenge der Daten aufgebaut, und an jedem Knoten wird eine zufällige Teilmenge von Merkmalen für die Aufteilung berücksichtigt. Dies führt zu einer Diversität zwischen den einzelnen Bäumen und macht das Ensemble robuster und weniger anfällig für Overfitting. Wenn ein neuer Datenpunkt klassifiziert werden muss, wird er durch jeden Entscheidungsbaum geleitet. Jeder Baum gibt seine eigene Klassifizierung ab, und die Klasse, die die meisten Stimmen erhält, wird zur Vorhersage des Ensembles.
Der Random Forest-Algorithmus wird häufig für Klassifizierungs- und Regressionsaufgaben verwendet. Er ist bekannt für seine Einfachheit und die Tatsache, dass er mit minimaler Abstimmung der Hyperparameter eine hohe Genauigkeit erreichen kann, was ihn zu einer guten Wahl für viele praktische Machine-Learning-Probleme macht.
Mixture of Experts
Ein Mixture of Experts (MoE) ist ein weiteres Beispiel für ein Ensemble, das sich jedoch von Methoden wie Random Forests oder Boosting durch seine Architektur und die Art und Weise, wie es verschiedene Modelle kombiniert, unterscheidet. Die Expertenmischung besteht aus zwei Hauptkomponenten: den "Experten", d. h. einzelnen Modellen, die für die Erstellung von Vorhersagen trainiert wurden, und einem "Gating-Netzwerk", das bestimmt, wie stark die Vorhersagen der einzelnen Experten bei der Erstellung der endgültigen Vorhersage gewichtet werden sollen.
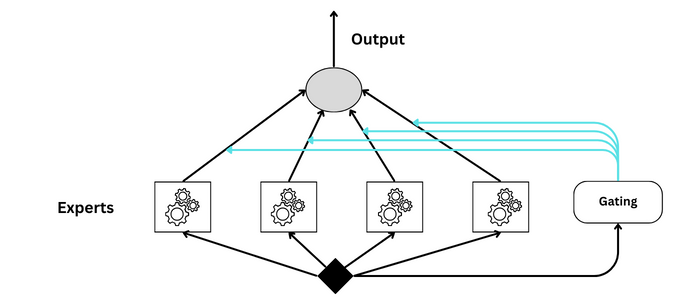
GPT
OpenAI hat die Verwendung von MoE in GPT-4 zwar nicht öffentlich erläutert, aber das Konzept passt gut zu den Zielen, anpassungsfähigere und leistungsfähigere KI-Systeme zu schaffen. Durch den Einsatz verschiedener spezialisierter Modelle könnte ein GPT-Modell mit MoE genauere, kontextgerechte und nuanciertere Antworten für ein breiteres Spektrum von Themen und Sprachen liefern als ein einzelnes, monolithisches Modell.
Der MoE-Ansatz ist ein Schritt in Richtung modularer und interpretierbarer KI-Systeme, bei denen die Beiträge der einzelnen Komponenten zum Endergebnis klarer sind. Dies könnte auch die Fehlersuche und die Verbesserung von KI-Modellen erleichtern, da jeder Experte unabhängig analysiert und feinabgestimmt werden kann. Im Zuge der weiteren Entwicklung der KI könnten Techniken wie MoE bei der Bewältigung der zunehmenden Komplexität und Leistungsfähigkeit von Modellen wie GPT von entscheidender Bedeutung sein.
Fazit
Zusammenfassend lässt sich sagen, dass Ensemble-Methoden einen bedeutenden Meilenstein in der Landschaft des maschinellen Lernens darstellen, da sie eine synergetische Strategie bieten, die oft die Leistung einzelner Modelle übertrifft.
Durch die Zusammenführung verschiedener Algorithmen verbessert das Ensemble-Lernen nicht nur die Vorhersagegenauigkeit, sondern auch die Verallgemeinerbarkeit der Modelle. In diesem Artikel wurde das Spektrum der Ensemble-Techniken - Bagging, Boosting und Stacking - durchlaufen, die alle in einzigartiger Weise zur Robustheit von Lösungen für das maschinelle Lernen beitragen.
Mit Blick auf die Zukunft versprechen Ensemble-Methoden weiterhin Fortschritte in der künstlichen Intelligenz und sind bereit, die Komplexität von Big Data und die Feinheiten realer Problemlösungen zu bewältigen. Für Anwender und Forscher gleichermaßen könnte die Nutzung dieser Techniken der Schlüssel zur Erschließung neuer Ebenen des KI-Potenzials sein.
Häufig gestellte Fragen
Ist SVM ein Ensemble-Algorithmus?
Die Support Vector Machine (SVM) wird nicht als Ensemble-Lernmethode betrachtet, da sie nicht mehrere Modelle kombiniert, um eine Vorhersage zu treffen. Ensemble-Methoden wie Bagging, Boosting oder Stacking beruhen auf der Aggregation der Ergebnisse mehrerer Basis-Learner, um die Vorhersageleistung zu verbessern. Im Gegensatz dazu ist SVM ein einzelnes Modell, das die optimale Hyperebene findet, um verschiedene Klassen im Merkmalsraum zu trennen. Es beinhaltet weder die Kombination mehrerer Modelle noch irgendeine Form der Modellmittelung oder -abstimmung, die das Markenzeichen des Ensemble-Lernens sind.
Warum ist Ensemble-Lernen besser als maschinelles Lernen?
Das Ensemble-Lernen ist nicht per se "besser" als das maschinelle Lernen; es ist vielmehr eine spezialisierte Technik innerhalb des umfassenderen Bereichs des maschinellen Lernens. Der Hauptvorteil des Ensemble-Lernens ist die Fähigkeit, die Vorhersageleistung eines Modells zu verbessern, indem mehrere schwächere Modelle zu einem stärkeren Modell kombiniert werden. Dies führt oft zu einem Modell, das sich besser auf neue, unbekannte Daten verallgemeinern lässt, wodurch die Wahrscheinlichkeit einer Überanpassung verringert wird.