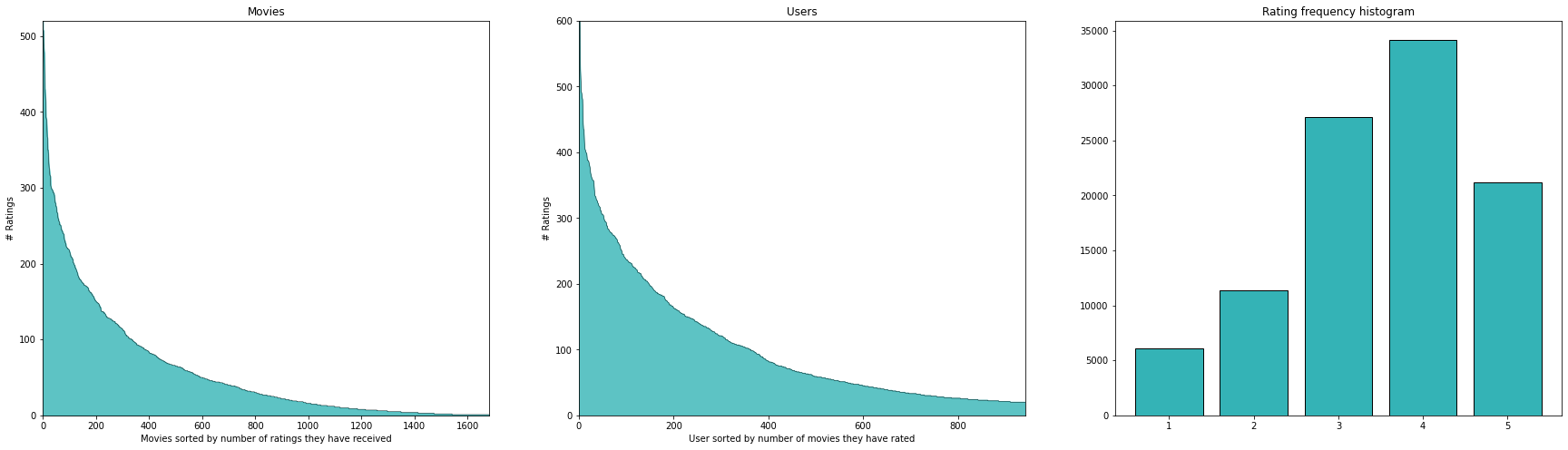
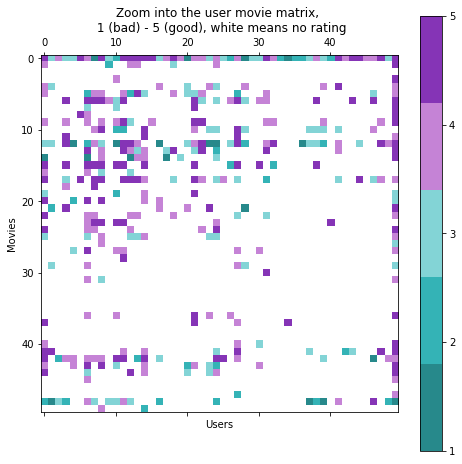
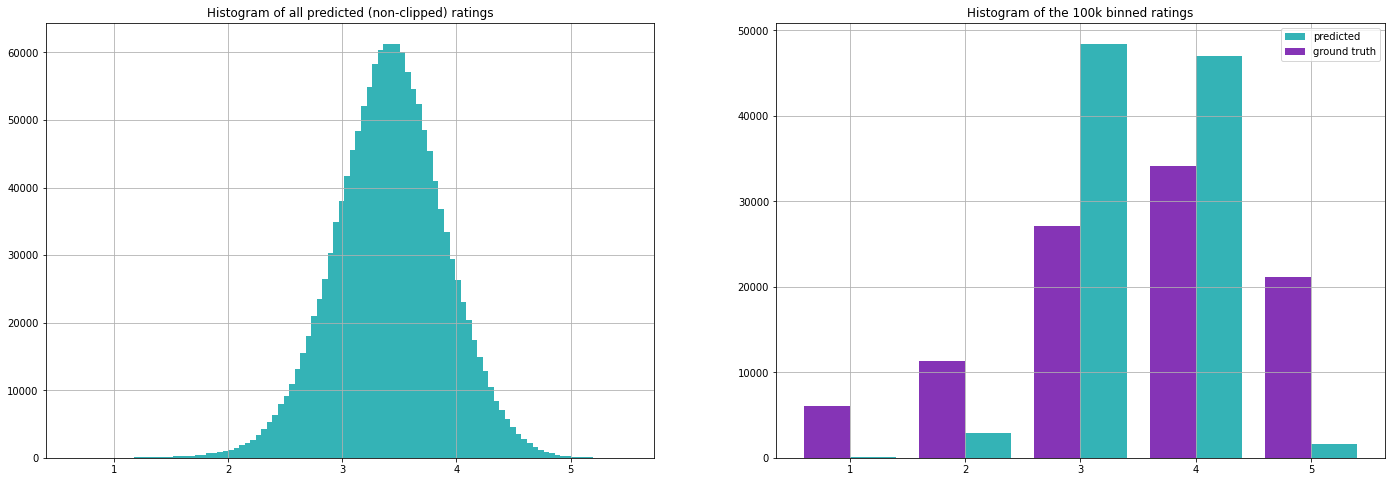
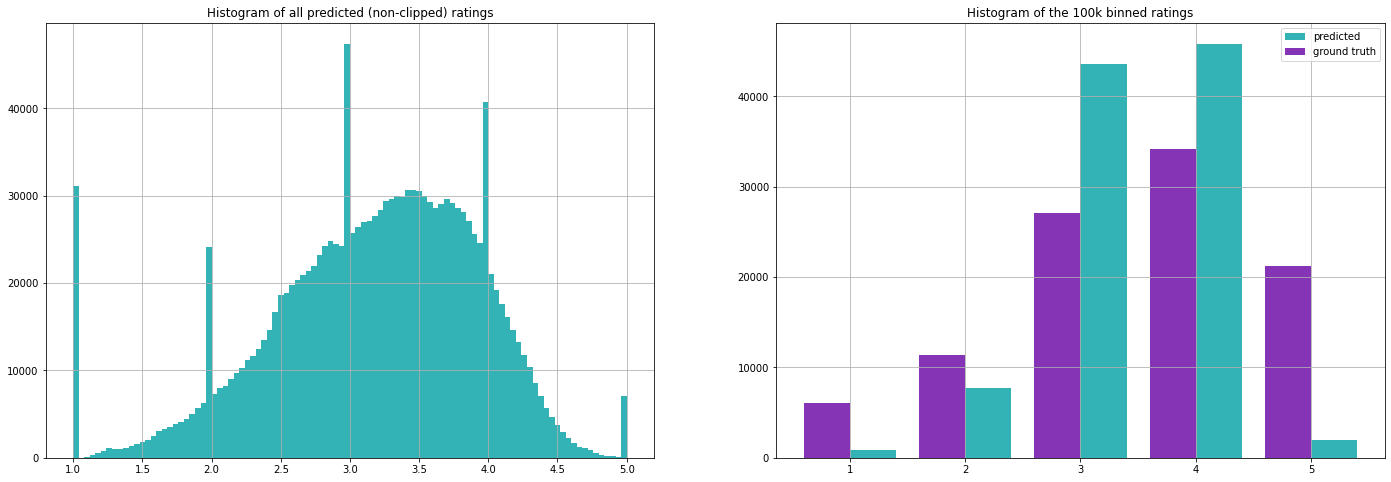
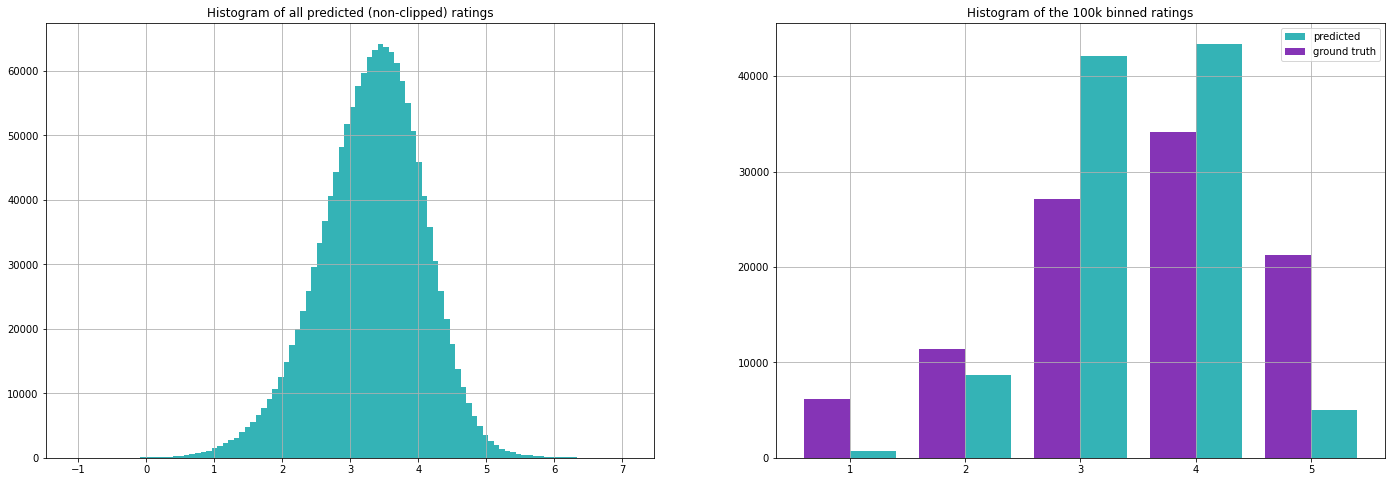
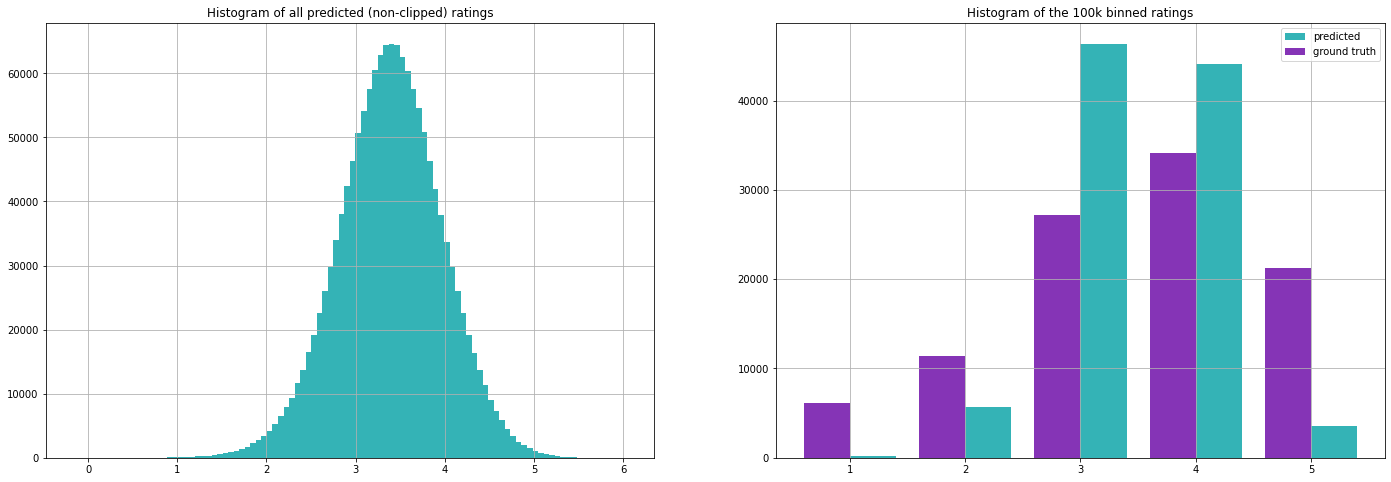
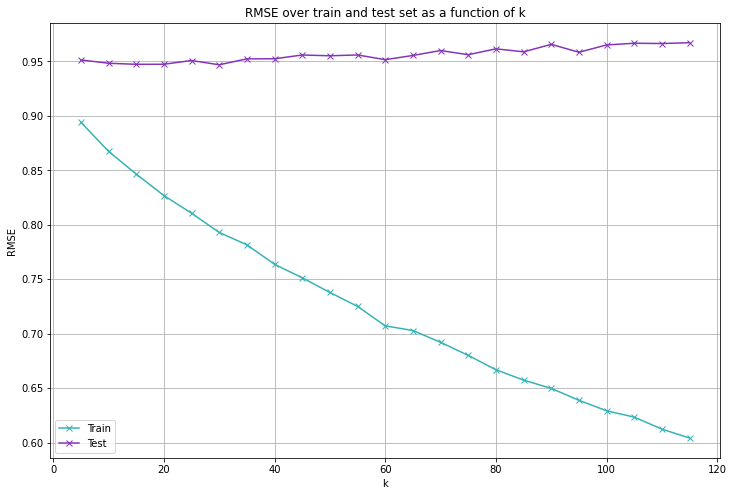
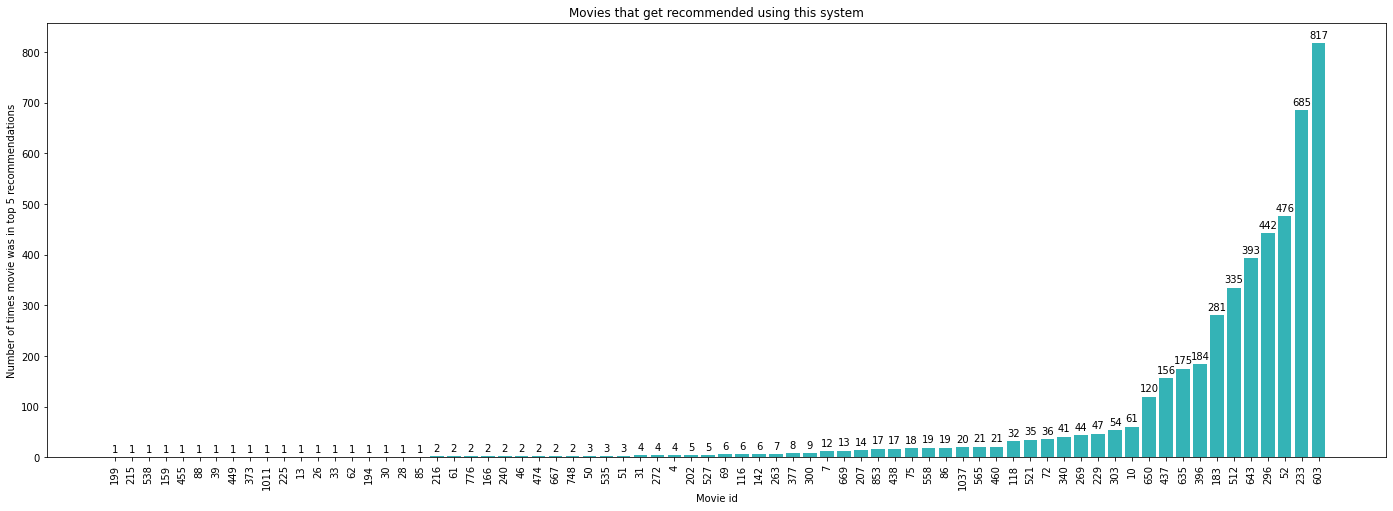
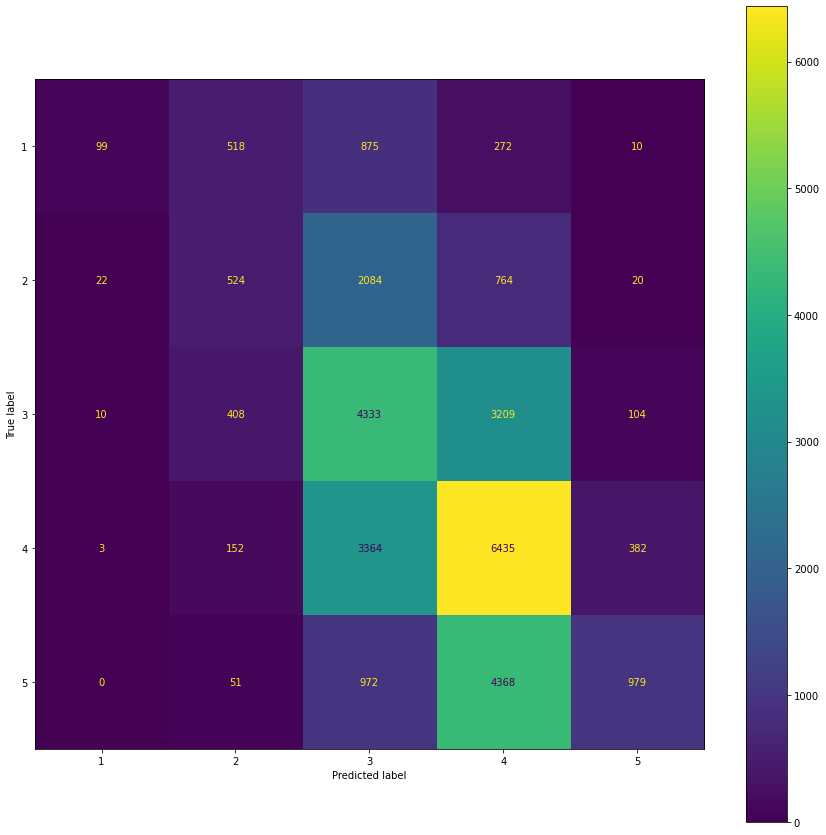
Die Auswertung unserer Testmenge ergibt folgende Kennzahlen (beachten Sie, dass wir die Mittelwerte nur auf der Trainingsmenge berechnet haben).
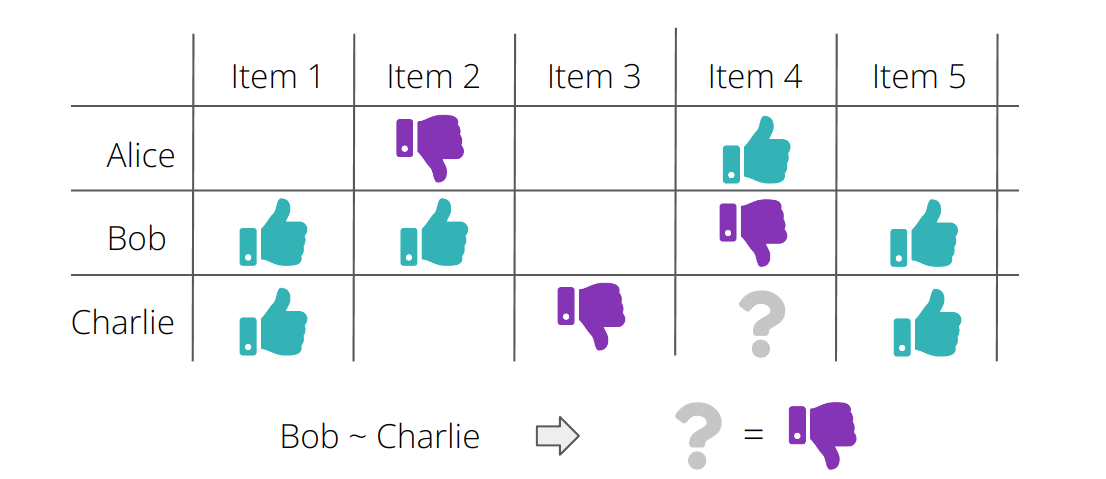
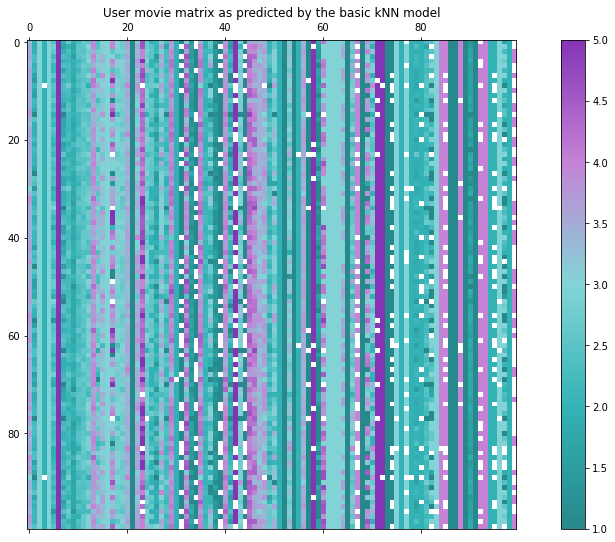
Dieser Ansatz ist definitiv nicht der ausgeklügeltste. Wir haben keinerlei Informationen über die Benutzer berücksichtigt, so dass wir keine personalisierten Empfehlungen erwarten können. Tatsächlich ist der Rang dieser Benutzer-Film-Matrix gleich 1, da alle Spalten konstant sind!
Aus reiner Neugierde können wir das Gleiche für die Benutzer tun. Beachten Sie jedoch, dass dies aus der Sicht einer Empfehlungsmaschine nutzlos ist, da alle Filme für jeden Benutzer die gleiche Bewertung haben. Wir erhalten die folgenden Metriken:
Wie wir später sehen werden, sind diese Metriken eigentlich gar nicht so schlecht. Dies verdeutlicht eine wichtige Herausforderung bei der Auswertung von Empfehlungssystemen, da beide Ansätze im Grunde nutzlos sind, wenn es darum geht, personalisierte Empfehlungen zu geben, aber dennoch anständige Ergebnisse liefern, wenn sie mit diesen Metriken bewertet werden. Der erste Ansatz wird jedoch häufig verwendet, wenn einfach keine Informationen verfügbar sind, z. B. wenn sich ein neuer Nutzer bei einem Streaming-Dienst anmeldet.
Der Algorithmus, der als Baseline von der surprise Bibliothek vorgeschlagen wird, ist etwas ausgefeilter. Er führt für jeden Benutzer und jeden Film einen (skalaren) bias ein, $$b_u$$ bzw. $$b_i$$. Diese Verzerrungen sind lernbare Parameter. Die Vorhersage ist dann definiert als