Frühzeitige Klassifizierung von Anbauflächen anhand von Satellitenbild-Zeitreihen
Tiago Sanona

In einer schnelllebigen und sich ständig verändernden globalen Wirtschaft bietet die Möglichkeit, Erntefelder am Ende eines Wachstumszyklus per Fernerkundung zu klassifizieren, nicht den dringend benötigten unmittelbaren Einblick, den die Entscheidungsträger benötigen. Um dieses Problem zu lösen, haben wir ein Modell entwickelt, das eine kontinuierliche Klassifizierung von Anbaufeldern zu jedem beliebigen Zeitpunkt ermöglicht und die Vorhersagen verbessert, sobald mehr Daten zur Verfügung stehen.
In der Praxis haben wir ein einziges Modell entwickelt, das in der Lage ist, auf der Grundlage von Satellitendaten Vorhersagen darüber zu treffen, welche Kulturen zu einem beliebigen Zeitpunkt im Anbau sind. Bei den Daten, die zum Zeitpunkt der Inferenz zur Verfügung stehen, kann es sich um einige wenige Bilder zu Beginn des Jahres oder um eine vollständige Zeitreihe von Bildern aus einer kompletten Wachstumsperiode handeln. Dies übersteigt die Möglichkeiten aktueller Deep-Learning-Lösungen, die entweder nur Vorhersagen am Ende der Vegetationsperiode bieten oder mehrere Modelle verwenden müssen, die auf Ergebnisse zu vorher festgelegten Zeitpunkten spezialisiert sind.
Dieser Artikel beschreibt die wichtigsten Änderungen, die wir an dem Modell vorgenommen haben, das in einem früheren Blog-Beitrag "Classification of Crop fields through Satellite Image Time Series" beschrieben wurde.
Die in diesem Artikel vorgestellten Ergebnisse beruhen auf einem kürzlich von der dida veröffentlichten Forschungspapier. Ausführlichere Informationen zu diesem Thema und weitere Experimente zu diesem Modell finden Sie im Originalmanuskript: "Early Crop Classification via Multi-Modal Satellite Data Fusion and Temporal Attention".
Kurzer Rückblick
Um ein überwachtes Modell zu trainieren, benötigt man gelabelte Daten. Unsere Daten basieren auf Paaren von Geometrien, die die Grenzen von Feldern und den Namen der auf diesen Feldern angebauten Pflanzen beschreiben (die Labels). Anhand der Geometrien können wir aus den Satelliten-Rohdaten (einer Zeitreihe von Bildern) die Zeitreihen von Pixeln extrahieren, die vom Modell auf die Labels abgebildet werden sollen. Was wir dann als Flurstück bezeichnen, ist dieses begrenzte Gebiet, das durch die Geometrie definiert ist und aus dem wir eine Sammlung von Pixeln haben, die wir vorhersagen wollen. Ein Pixel ist ein eindimensionaler Vektor mit einer Länge, die der Anzahl der Kanäle des Bildes entspricht, von dem es aufgenommen wurde.
Es ist auch wichtig zu beachten, dass die Bilder hier nicht genau die gleichen sind wie die üblichen Bilder, an die wir gewöhnt sind. In diesem Zusammenhang besteht ein Bild aus vielen Kanälen (je nach Quelle) im Gegensatz zu den üblichen drei Kanälen (RGB).
Das Innenleben des Modells kann dann in drei Teile aufgeteilt werden:
Pixel-Set-Codierer: Hier erstellt das Modell eine Zeitreihe von Einbettungen der Rohdaten, indem es Stichproben von Pixeln aus einem Flurstück kodiert.
Zeitlicher Attention-Encoder: Hier werden die vorherigen Zeitreihen durch eine Variation des Transformers von Vaswani et al. geleitet, der einen einzigen Tensor als Ausgabe erzeugt.
Klassifikator: Hier wird der vorherige Tensor verwendet, um eine Pflanzenklasse zu bestimmen.
Im Blogbeitrag "Classification of Crop fields through Satellite Image Time Series" werden all diese Konzepte näher erläutert.
Datenfusion: gemeinsame Nutzung von Sentinel-1 und Sentinel-2
Die erste Änderung, die wir vorgenommen haben, war die Verwendung multimodaler Daten zur Klassifizierung der Felder. Inspiriert durch frühere Studien (Garnot et. al, Ofori-Ampofo et. al) haben wir beschlossen, Sentinel-1 (SAR-Daten, auch bekannt als Radardaten) neben Sentinel-2 (optische und Infrarotdaten) einzubeziehen. Der Grund für die Verwendung von Sentinel-1 (S1) ist, dass es zwei Einschränkungen bei Sentinel-2 (S2) gibt, die die Verfügbarkeit der Daten einschränken:
Wolkenabdeckung: S2 sammelt Daten innerhalb eines Intervalls des elektromagnetischen Spektrums, das Wolken nicht durchdringen kann. Das bedeutet, dass bei Vorhandensein einer Wolke im Sichtfeld des Satelliten keine Daten vom Boden unter der Wolke erfasst werden.
Tageslicht: S2 ist darauf ausgelegt, Bilder mit Hilfe des von der Erde reflektierten Sonnenlichts zu erstellen. Daher kann er nur dann Daten sammeln, wenn der Bereich, den er überfliegt, von der Sonne beleuchtet wird.
Die Daten von S1 hingegen können verwendet werden, um diese fehlenden Datenpunkte zu kompensieren, da sie nicht unter diesen Einschränkungen leiden. Sie verfügen nicht nur über eine eigene Quelle elektromagnetischer Strahlung, sondern die Art der Strahlung, die sie erzeugen (Radiowellen), kann auch Wolken durchdringen und die darunter liegenden Oberflächeninformationen abrufen.
Das Problem dabei ist, dass die Beobachtungen aus beiden Quellen zu unterschiedlichen Zeitpunkten erfolgen. Die folgende Abbildung zeigt das Auftreten von Daten aus beiden Datenquellen für zwei verschiedene Flurstücke im Laufe eines Jahres. Man kann sehen, wie sich die Zeitstempel der Beobachtungen nicht nur zwischen den Quellen (S1 und S2), sondern auch zwischen den Beobachtungen derselben Quelle auf verschiedenen Flurstücken (A und B) unterscheiden.

Es gibt verschiedene Möglichkeiten, sequentielle Daten, die nicht dieselbe zeitliche Verfügbarkeit haben, zusammenzuführen. Sie unterscheiden sich darin, wann (und wie) die Daten aus den verschiedenen Quellen zusammengeführt werden. Für unsere Zwecke haben wir uns für die frühe Fusion ("early fusion") entschieden, da die Autoren der oben genannten Arbeiten nachgewiesen haben, dass sie das speichereffizienteste der Fusionsmodelle ist und im Vergleich zu Modellen, die einzelne Quellen verwenden, erhebliche Leistungssteigerungen aufweist.
Bei der frühen Fusion werden die Daten der Quellen kombiniert, bevor sie in das Modell eingespeist werden. Die Bilder von S1 und S2 werden in der Regel so interpoliert, dass die Zeitreihen in ihrer Länge übereinstimmen. So entstehen zwei neue Zeitreihen mit Datenpunkten zu übereinstimmenden Zeiten. Auf diese Weise kann die Fusion auf Kanalebene erfolgen, d. h. man kann einfach alle Kanäle der Bilder stapeln, die im Zeitstempel übereinstimmen. Auf diese Weise entsteht eine neue Zeitreihe, bei der jedes Bild aus den Kanälen von S1 und S2 zusammengesetzt ist.

Wir führen auch eine Neuerung ein, denn wir überspringen den Interpolationsschritt ("temporal resampling" in der Skizze von Garnot et al.), indem wir die Reihen einer der beiden Quellen einfach auffüllen, wenn eine passende zeitliche Beobachtung nicht verfügbar ist. Das bedeutet, dass immer dann, wenn es eine Beobachtung, z. B. aus S1, gibt, der keine entsprechende S2-Beobachtung gegenübersteht, die fusionierte Reihe diese S1-Beobachtung enthält, die mit einem Wert für "fehlende Daten" anstelle der fehlenden S2-Daten verkettet ist.
Schließlich löst die Verwendung eines solchen Modells (eines Transformators) das Problem, dass verschiedene Pakete mit völlig unterschiedlichen Zeitreihen in Bezug auf Länge und Häufigkeit der Daten vorliegen. Wie bereits im vorherigen Blog-Beitrag erwähnt, ist eine der Komponenten des Modells der Positionskodierer. Diese Komponente nimmt zusammen mit den für die Vorhersage verwendeten Pixeln eine Liste mit den Erfassungsdaten der Pixel auf. Diese teilen dem Modell im Wesentlichen mit, wie diese Pixel in der Zeit positioniert sind. Dadurch erhält das Modell eine Art zusätzliche Dimension für den Vergleich von Zeitreihen; das Modell muss sich nicht auf Vergleiche zwischen Datenpunkten mit demselben Index beschränken und kann komplexere Beziehungen innerhalb und zwischen Zeitreihen wahrnehmen.
Die nachstehende Tabelle zeigt die Ergebnisse der Bewertung des Modells mit und ohne Fusion von Quellen. Das Modell wurde mit Daten aus der Wachstumsperiode 2018 trainiert und bewertet. Wie in der Tabelle zu sehen ist, steigt die Leistung des Modells bei Verwendung fusionierter Daten im Vergleich zur Verwendung einer einzelnen Quelle. Dies ist darauf zurückzuführen, dass das Modell nun Zugang zu einigen der Informationen hat, die aufgrund der Nichtverfügbarkeit der S2-Daten fehlen. Dies bedeutet auch, dass das Modell in Regionen, in denen die Wolkenverdeckung ein größeres Problem darstellt (d.h es gibt sogar weniger verfügbare S2-Bilder), immer noch gute Leistungen erbringen dürfte.
Quelle |
F1-Score |
S1 |
0.84 |
S2 |
0.87 |
S1 + S2 |
0.89 |
Frühzeitige Klassifizierung
Das Hauptziel unseres Projekts bestand darin, eine plausible Klassifizierung eines Flurstücks so früh wie möglich innerhalb seiner Wachstumsperiode zu erreichen. Auch hier gibt es viele Möglichkeiten, um eine frühe Klassifizierung zu erreichen:
Gleiches Modell, verschiedene Zeitpunkte: Dies bedeutet im Grunde, dass man für jeden der Zeiträume, für die eine Vorhersage benötigt wird, ein Modell trainiert.
Fruchtfolgemuster: Die Idee hinter diesem Konzept ist, dass bestimmte Kulturen dazu neigen, in einer vorhersehbaren Weise zu rotieren, d. h. Landwirte pflanzen diese Kulturen nach einem erkennbaren Muster nacheinander an. Durch die Verwendung eines Modells, das anhand von Daten aus vielen Jahren trainiert wurde, ist das Modell in der Lage, diese Muster zu erkennen und daraus abzuleiten, was gerade wächst, bevor es überhaupt gepflanzt wird.
Expertenbasiertes Modell: Einige Forscher sind auch in der Lage, Modelle auf der Grundlage ihres Fachwissens über die Pflanzen zu erstellen. Sie können ihr Wissen darüber, wie die Daten für eine bestimmte Pflanze zu einem bestimmten Zeitpunkt "aussehen", nutzen, um einen Entscheidungsbaum zu erstellen, der zu einer korrekten Klassifizierung der Pflanze führt, ohne ein Modell trainieren zu müssen.
Unsere Lösung bestand darin, einfach ein Modell auf zufällig maskierten Zeitreihen zu trainieren: Während des Trainings augmentierten wir unsere Daten, indem wir die Daten der Zeitreihen jedes Flurstücks nach einer bestimmten Anzahl von Tagen ab deren Beginn zufällig unkenntlich machten. Auf diese Weise erhält das Modell Beispiele dafür, welche Daten für eine Klassifizierung zu einem früheren Zeitpunkt in der Wachstumsperiode zur Verfügung stehen würden. Dadurch ist das Modell gezwungen, sich nicht immer auf die gesamte Zeitreihe (von der Aussaat bis zur Ernte) zu verlassen, sondern andere Muster in den Daten zu finden, um Vorhersagen treffen zu können. Das bedeutet auch, dass das Modell unvollständige Zeitreihen von Daten sinnvoll nutzen kann, um frühe Vorhersagen zu erstellen.
Unten sehen wir eine Darstellung dieser frühen Klassifizierungstechnik mit einem Diagramm, das zeigt, wie die Leistung des Modells (bis zu einem gewissen Punkt) mit der Menge der verfügbaren Daten aus der Wachstumsperiode wächst.

Hier zeigen wir auch, wie sich die Leistung des Modells mit der zeitlichen Verfügbarkeit von Daten verändert, insbesondere für Raps und Zuckerrüben. Die grün und gelb schattierten Bereiche stellen die Zeiträume dar, in denen diese Kulturen normalerweise gesät bzw. geerntet werden. Die Farben der Linien haben die gleiche Legende wie in der vorherigen Abbildung.

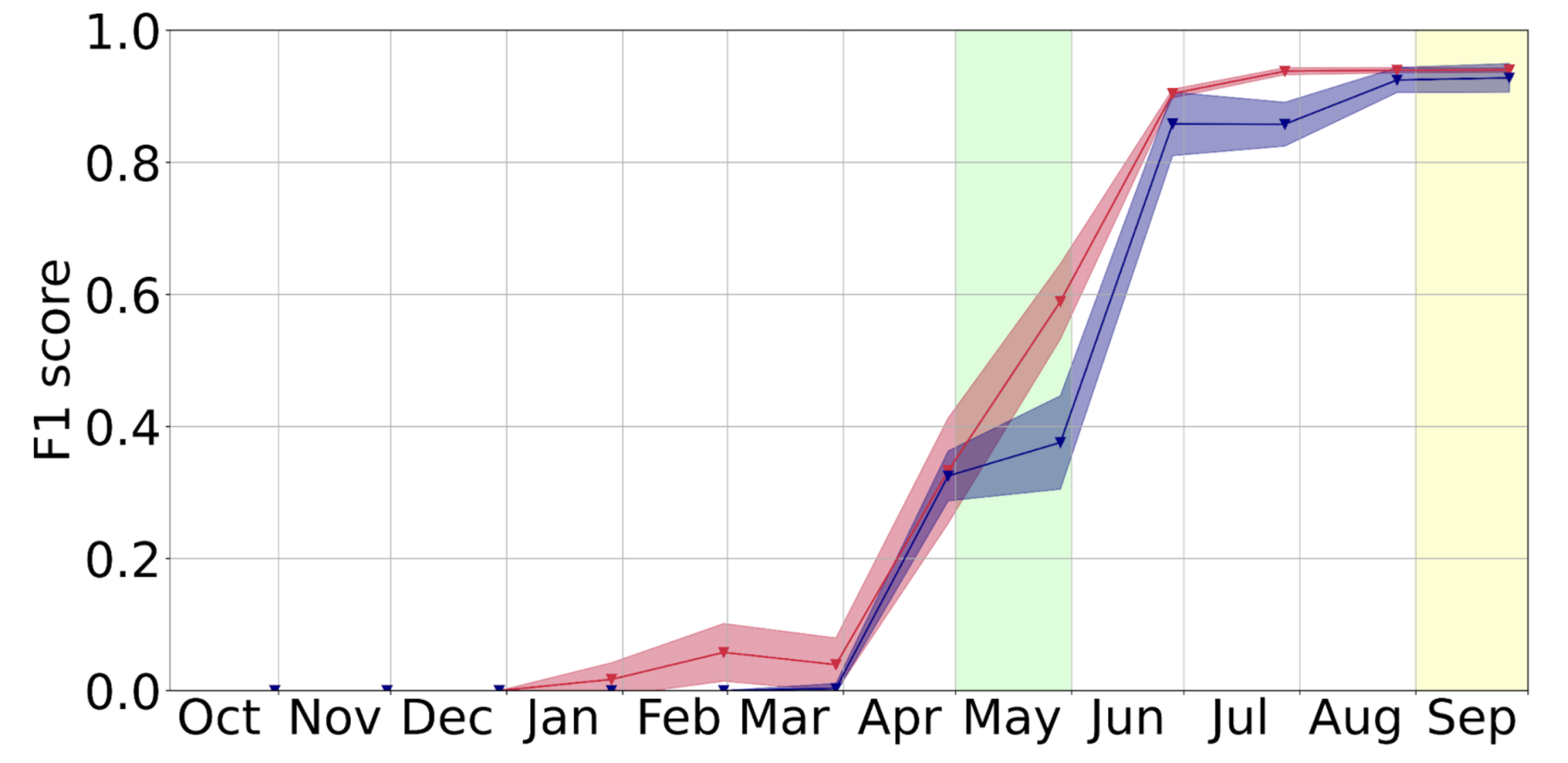
In den obigen Abbildungen enthalten die Diagramme zwei Linien, eine für die Jahre 2018 und 2019 und eine für das Jahr 2020. Sie zeigen die F1-Werte an, die das Modell bei der Auswertung eines Datums aus diesen Jahren erzielt hat. Das Modell wurde immer mit Daten aus den Jahren 2018 und 2019 trainiert. Ein weiterer wichtiger Aspekt sind die Bänder um die Linien. Diese stellen den Mittelwert (die Linie) und die Standardabweichung der Ergebnisse dar, die bei der Auswertung verschiedener Trainingsinstanzen des Modells erzielt wurden.
Fazit
Dieser Artikel zeigt, wie das Modell in "Classification of Crop fields through Satellite Image Time Series" verändert wurde, um andere Datenquellen nutzen zu können und eine frühzeitige Klassifizierung durchzuführen. Für ausführlichere Erklärungen, wie wir diese Ergebnisse erzielt haben, können Sie gerne unser veröffentlichtes Papier zu diesem Thema mit dem Titel "Early Crop Classification via Multi-Modal Satellite Data Fusion and Temporal Attention" lesen.